Теория: Лекция [Все занятия]
Практика: [Официальная страница]
Учебные задачи:
Задача A.
[Сортировка]
На этой задаче можно тестировать корректность работы “быстрых” сортировок.
Задача B.
[Хеширование с удалением]
На момент 26Sep2011 15:59 данная реализация получала RE на 8 тесте. Верное решение 2-х летней давности получала тот же вердикт. Проблема связана с нехваткой памяти, вызванное переходом на 64 битную версию линукса, стоящего на сервере проверяющей системы.
Эту задачу можно сдать с текущими ограничениями с помощью хеширования(алгоритм Рабина-Карпа) или с помощью построения дерева(алгоритм Ахо-Корасик), но т.к. данная задача предусматривалась в рамках учебных задач на STL, то условимся, что решение с использованием set нас полностью устраивает.
Задача С.
[Двоичный поиск]
А на этой задаче можно тестировать рукописную дихотомию.
Олимпиадные задачи:
Задача A.
[Сплоченная команда]
Решение получилось прям очень STL’вским) Сначала сортируем игроком по их ПП. Далее последовательно перебираем пары двух игроков G1 и G2, стоящих рядом. Сумма их ПП определяет значение ПП максимального игрока G3 в команде. G3<=G1+G2. Чтобы найти позицию игрока G3 максимально удовлетворяющему игрокам G1 и G2 можно воспользоваться функцией upper_bound на отсортированном массиве игроков. Чтобы найти сумму игроков в команде за O(1), можно заранее сделать подсчет интервальных подсумм.
Задача B.
[Древние цивилизации] Ответ за O(NlogN): multiset
Написал небольшого монстрика, который сильно перегружен STL. Но зато я впервые попользовался обратными итераторами (reverse_iterator). Восстановление ответа использует multiset. Это связано с компаратором. На самом деле основная идея лучше реализована в исходнике двух летней давности, который находится ниже. Там восстановление ответа написано тоже за O(NlogN), но константа будет меньше. Этот исходник выкладываю исключительно для себя, чтобы в следующий раз такого не делать).
[Древние цивилизации] Ответ за O(N)
Самая адекватная реализации данной задачи. Очередной пример того, что не надо нагружать программу красивыми фенечками, вместо того, чтобы немного подумать. Можно заметить, что нужный интервал будет образовываться между двумя соседними историческими событиями. Под историческим событием я понимаю либо зарождение, либо гибель одной из цивилизаций. При этом левой границей интервала будет зарождение, а правой – гибель цивилизации. Крайний случай будет если нужный интервал совпадает с периодом одной из цивилизации (назовем ее цивилизации A). В крайнем случае нужно найти вторую цивилизацию, которая существовала до цивилизации A а погибла после. Это можно сделать за O(N).
[Древние цивилизации] Ответ за O(NlogN): set [25Nov2009]
Данное решение выкладываю тоже исключительно для себя. Логарифм в сложности вылезает из-за крайнего случая, описанного во втором решении. Я пытался сразу обрабатывать крайний случай для поиска второй цивилизации. Это приводило к тому, что все зародившиеся множества клались в множество, а при гибели они из этого множества удалялись. Как известно каждая операция выполняется за O(logN).
Задача С.
[Число]
Идентичная задача была на ACM ICPC Subregional Contest 2007 в Саратове. Вот она на сервере acm.sgu.ru. Приятно вспомнить, что тогда мы ее зачли). Спасибо Роману и Рамилю.
Дополнительные олимпиадные задачи:
Задача A.
[Современники]
Задача на сканирующую линию. Создаем массив из дат. Для каждой даты храним метку, является ли она началом периода или концом. В качестве даты нужно добавлять день [18-летия](начало) и день [80-летия – 1 день](конец). Небольшая сложность состоит в подсчете даты [80-летия – 1 день]. Для этого нужно аккуратно выписать количество дней в месяцах и не забыть обработать случай високосного года.
Задача B.
[Контрольная по ударениям]
Задача на быстрое нахождение слова в словаре. По ходу решения удобно завести два множества. В первом будем хранить слова с ударением, а во втором – те же слова в нижнем регистре для определения наличия слова без проверки на ударение.
Задача С.
[Умный чертежник] Сложное решение =)
По условию задачи робот не может проехать по нарисованной ранее линии. Можно представить перемещения работа в виде графа. Этот граф будет представлен либо Эйлеровым путем, либо Эйлеровым циклом(справка). Следовательно либо все степени вершин графа являются четными(Эйлеров цикл), либо 2 вершины имеют нечетную степень,а все остальные четную(Эйлеров путь). Также отметим, что граф является связным. Суть данного решения заключается в том, что мы двигаемся по исходному графу как захотим. Во время движения не меняем направления только в том случае, если этого сделать нельзя. Т.е. избегаем комбинаций в маршруте типа “EE”, “WWW” и подобных, если это возможно. Такая тактика приведет к тому, что все вершины с нечетными степенями будут содержаться в нашем пути. Но может возникнуть ситуация, когда некоторые вершины будут не использованы в маршруте. Неиспользованные вершины будут образовывать конечное количество циклов. Чтобы все неиспользованные циклы добавить в ответ нужно найти место в ответе, куда нужно их вставить. Эту операцию можно сделать путем пересечения множеств использованных и неиспользованных вершин. Вершина считается использованной, если не осталось неиспользованных ребер, исходящих из нее. Поясним более наглядно вышесказанное.
Исходный путь: NNWSEE
Первоначальный путь: NE
В результате остался неиспользованный цикл WNES. Его нужно вставить после первого шага. В итоге получаем ответ: NWNESE
[Умный чертежник] Простое решение !
Предыдущее решение было не очень продуманным в плане простоты реализации. Если подумать, можно заметить, что если робот наткнулся на самопересечение в точке P, то нужно двигаться в обратную сторону между двумя попаданиями в точку P в рамках первоначального пути. Важно учесть, что после такого “реверса” пути заново пройти весь путь с первоначального попадания в точку P, чтобы проверить наличие самопересечений последующего пути с “реверснутым” подпутем.
понедельник, 26 сентября 2011 г.
Занятие №5. STL
Поразрядная сортировка (Radix_sort)
[Все сортировки]
Теория: Wikipedia
Практика: acmp.ru
Реализация:
Условимся, что мы обрабатываем только массив неотрицательных целых чисел.
Первая реализация обрабатывает разряды десятичного числа начиная с младших. Количество разрядов в числе задается в константе RADIX_AMOUNT.
- typedef unsigned int UINT;
- . . .
- void radix_sort10(UINT* &a, int size) {
- UINT* b = new UINT[size];
- UINT* title = new UINT[10];
- UINT* count = new UINT[10];
- UINT* prev = new UINT[size];
-
- memset(count,0,sizeof(UINT) * 10);
- char curDig;
- int osn = 10;
- int del = 1;
- for (int r=0;r<RADIX_AMOUNT;r++) {
- for (int i=0;i<size;i++) {
- curDig = (a[i] % osn) / del;
- prev[i] = title[curDig];
- title[curDig] = i;
- count[curDig]++;
- }
- int bPos = size;
- for (int i=9;i>=0;i--) {
- while (count[i]) {
- b[--bPos] = a[title[i]];
- title[i] = prev[title[i]];
- count[i]--;
- }
- }
- osn *= 10; del *= 10;
- swap(a,b);
- }
- delete[] b;
- delete[] title;
- delete[] count;
- delete[] prev;
- }
* This source code was highlighted with Source Code Highlighter.Вторая реализация обрабатывает цифру, состоящую из 8 байт. Т.е. исходное число обрабатывается в системе счисления с основанием 256 и содержит не более 4 цифр.
- void radix_sort256(UINT* &a, int size) {
- UINT* b = new UINT[size];
- UINT* title = new UINT[256];
- UINT* count = new UINT[256];
- UINT* prev = new UINT[size];
- UINT mask[4] = {0x000000FF,
- 0x0000FF00,
- 0x00FF0000,
- 0xFF000000};
-
- memset(count,0,sizeof(UINT) * 256);
- unsigned char curDig;
- for (int r=0;r<1;r++) {
- for (int i=0;i<size;i++) {
- curDig = a[i] & mask[r];
- prev[i] = title[curDig];
- title[curDig] = i;
- count[curDig]++;
- }
- int bPos = size;
- for (int i=255;i>=0;i--) {
- while (count[i]) {
- b[--bPos] = a[title[i]];
- title[i] = prev[title[i]];
- count[i]--;
- }
- }
- swap(a,b);
- }
- delete[] b;
- delete[] title;
- delete[] count;
- delete[] prev;
- }
* This source code was highlighted with Source Code Highlighter.воскресенье, 25 сентября 2011 г.
Сортировка подсчетом (Counting sort)
[Все сортировки]
Теория: Wikipedia
Практика: acmp.ru
Реализация:
- void counting_sort(vector<int> &mas) {
- vector<int> amount(MAX_VALUE,0);
- for (int i=0;i<mas.size();i++)
- amount[mas[i]]++;
- int pos = -1;
- for (int i=0;i<MAX_VALUE;i++)
- for (int j=0;j<amount[i];j++)
- mas[++pos] = i;
- }
* This source code was highlighted with Source Code Highlighter.четверг, 22 сентября 2011 г.
Занятие №4. Алгоритмы сортировки
Теория: Лекция [Все занятия]
Практика: [Официальная страница]
Учебные задачи:
Задача A.
[Пузырьковая сортировка: количество обменов]
Классическая задача на пузырек.
Задача B.
[Разные]
Еще одна классическая задача, для которой нужно применить квазилинейную сортировку.
Задача С.
[Объединение последовательностей]
Задача на слияние двух отсортированных массивов.
Олимпиадные задачи:
Задача A.
[Ожерелье]
Довольно занятная задача. Пришлось подумать. Пока думал настрогал прожку, которая bfs’ом находит оптимальную стратегию. Только после этого решение стало очевидно).
Задача B.
[Головоломка]
Очень любопытная задача. Интересно всегда наблюдать за тем, как люди(и я в том числе) пишут симулятор разгадывания головоломки с помощью DFS или BFS, а потом с криками матерного содержания переписывают решение за 3 минуты и получают законные Accepted.
Задача С.
[НГУ-стройка]
Задача кажется с первого взгляда неприступной. Но если хорошенько присмотреться, то все не так страшно. Первое что нужно понять, как будет выглядеть сечение блоков, если зафиксировать конкретное значение Z. Это будет набор взаимно непересекающихся прямоугольников. Чтобы проверить покрывают ли эти прямоугольники всю область достаточно найти сумму их площадей. Общая идея решения изложена в лекции п.9. Сканирующая прямая.
Дополнительные олимпиадные задачи:
Задача A.
[Эльфы и олени]
Одна из тех задач, где жадность приводит к правильному ответу. Сортируем в порядке неубывания массив эльфов и оленей. Бинарным поиском подбираем K - количество оленей, которые попадут в упряжку. Чтобы проверить можно ли запрячь K оленей применяем следующую эвристику. Выбираем K минимальных эльфов и K максимальных. Группируем этих 2K эльфов по парам, чтобы обеспечить максимальное покрытие диапазона, которые занимают эльфы. Получаем: (1, N – K + 1), (2, N – K + 2) и т.д., где N – количество эльфов. С учетом выбранных пар утверждаем, что никакое другое деление на пары не увеличит количество оленей в ответе. Далее необходимо фиксировать выбранную пару эльфов и искать для него минимально возможного оленя.
Приведенное решения полностью идентично разбору Александра Чистякова с одним отличием, что для фиксированной пары эльфов можно находить оленя за O(logM) с помощью функции lower_bound, а не за O(M).
Задача B.
[Субботник]
Сортируем человечков по росту. Бинарным поиском по ответу подбираем ответ на задачу, а именно наименьшее возможное значение максимального числа неудобства. Для того, чтобы проверить корректность выбранного ответа последовательно перебираем слева направо группы из подряд идущих С человечков. Считаем количество групп, которые удовлетворяют выбранному ответу. Если их количество не меньше заявленного в условии R, то выбранный ответ является корректным. Такая жадность дает корректный ответ.
Задача С.
[Палиндром]
Довольно простая задача на сортировку подсчетом.
вторник, 20 сентября 2011 г.
Быстрая сортировка (Quick Sort) за O(NlogN) в среднем случае
[Все сортировки]
Теория: k-ая порядковая статистика
Практика: informatics.mccme.ru
Визуализатор: youtube.com [Adobe Flash Player]
Реализация:
- int partition(vector<int> &mas, int l, int r) {
- int pos = l-1;
- for (int i = l; i <= r; ++i) {
- if (mas[i] <= mas[r] )
- swap(mas[++pos], mas[i]);
- }
- return pos;
- }
- void quick_sort(vector<int> &mas, int l, int r) {
- if (l >= r) return;
- int pivot = partition(mas,l,r);
- quick_sort(mas,l,pivot-1);
- quick_sort(mas,pivot+1,r);
- }
* This source code was highlighted with Source Code Highlighter.Данная реализация на предложенной задаче работает в 2 раза быстрее(0.059 c), чем heap_sort(0.122 c).
K-ая порядковая статистика за O(N) в среднем случае
Потратил значительное время на поиск красивой реализации данного алгоритма. Как и следовало ожидать она лежала прямо под носом
- int partition(vector<int> &mas, int l, int r) {
- if (l!=r)
- swap(mas[l + rand() % (r - l)], mas[r]);
- int x = mas[r];
- int i = l-1;
- for (int j = l; j <= r; j++) {
- if (mas[j] <= x)
- swap(mas[++i],mas[j]);
- }
- return i;
- }
- int nth(vector<int> mas, int n) {
- int l = 0, r = mas.size() - 1;
- for(;;) {
- int pos = partition(mas,l,r);
- if (pos < n)
- l = pos + 1;
- else if (pos > n)
- r = pos - 1;
- else return mas[n];
- }
- }
* This source code was highlighted with Source Code Highlighter.Немного проанализируем представленный код.
Функция nth принимает на вход массив и номер порядковой статистики, которую нужно найти. После выполнения функция возвращает значение порядковой статистики.
Но куда большее значение имеет функция partition. Суть ее заключается в том, что она выбирает произвольный элемент массива mas, индекс которого находится в интервале [l,r] и ставит его на “свое место”, т.е. на то место, на котором находился элемент, если бы массив был упорядочен. 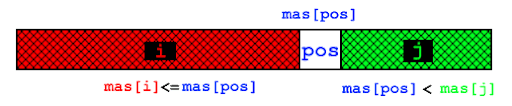 В строке 3 как раз и происходит выбор этого произвольного элемента. После чего выбранный элемент меняется местами с последним элементом рассматриваемого интервала.
В строке 3 как раз и происходит выбор этого произвольного элемента. После чего выбранный элемент меняется местами с последним элементом рассматриваемого интервала.
Если в качестве произвольного элемента брать всегда последний элемент или какой-нибудь фиксированный, то при желании можно легко подобрать тест, на котором представленная реализация будет иметь квадратичную сложность. Кстати если исходный массив будет упорядочен и в реализации функции partition будут отсутствовать 2 и 3 строки, то в каждой итерации функции nth на “свое место” будет становится только последний элемент и это будет повторяться SIZE раз, где SIZE – размерность массива.
На произвольном массиве данная реализация работает в среднем за O(N). Реализацию данного алгоритма при которой он будет работать за O(N) на любом массиве мы рассмотрим позже.
Обратите внимание, что в приведенной реализации массив передается по значению. Это следует делать, если мы незаинтересованы в частичном упорядочивании массива. В противном случае массив следует передавать по ссылке.
P.S: Если исходный массив будет состоять из одинаковых элементов, то приведенный алгоритм будет работать за O(N*N).
